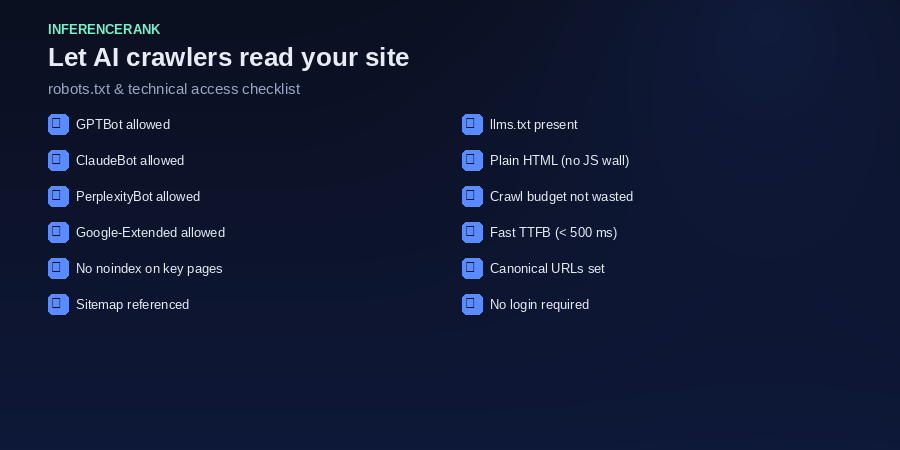
Which crawlers should I allow?
The ones that feed the answer engines your customers use. The common ones today are OpenAI's GPTBot and OAI-SearchBot, ClaudeBot, PerplexityBot, and Google's Google-Extended token. Allowing them lets those systems crawl and cite you. Blocking them — which some sites do by default or via a CDN setting — guarantees you're invisible to that engine.
Many CMS platforms and WAF rules block unknown bots by default. GPTBot, ClaudeBot, and PerplexityBot all identify themselves — make sure your robots.txt explicitly allows them.
What does the robots.txt look like?
Explicitly allow the bots you want, then point them at your sitemap. A permissive baseline is simply not disallowing them. For example:
User-agent: GPTBot — Allow: /. Repeat for ClaudeBot, PerplexityBot, Google-Extended, and OAI-SearchBot. Then add Sitemap: https://yourdomain/sitemap.xml. Keep it boring and explicit; ambiguity is where access quietly breaks.
Why does JavaScript rendering matter?
Many AI crawlers fetch your raw HTML and don't run JavaScript the way a browser does. If your content is injected client-side by a framework, the crawler sees an empty shell and has nothing to cite. The fix is to ship the actual content in the HTML the server returns — server-render or pre-render it — so it's readable without executing code.
What is llms.txt and should I have one?
An llms.txt file at your site root is an emerging convention: a short markdown map that tells models what your site covers and links to your key pages with descriptions. It's the cleanest way to hand models an overview on purpose. Few sites have one yet, so it's a cheap way to lead.
How do I confirm it's working?
Check your server logs for the bot user-agents to confirm they're fetching and not getting 403s, fetch your own pages as plain HTML (view source, not the rendered DOM) to confirm the content is there, and validate that robots.txt, sitemap.xml, and llms.txt return 200. If all three are true, the door is open.
The short version
Allow the AI bots, serve real HTML, publish a sitemap and an llms.txt, and verify with your logs. Access is table stakes — everything else in GEO assumes the crawler got in.