Traditional search vs AI search
In traditional search, a query is matched against an index, documents are ranked by relevance and authority signals, and the user gets a list of links to follow. The search engine's job ends when it hands over the list. In AI search, the engine doesn't hand over a list — it reads several sources on the user's behalf and writes a new response summarizing what they say. The user never has to click at all, which is why click-through rates from AI-generated answers are structurally lower than from a ranked link.
What is retrieval-augmented generation?
Most AI answer engines use a technique called retrieval-augmented generation (RAG). When a query arrives, the system first searches a web index (or a curated corpus) for documents likely to contain the answer. Those documents — or the most relevant passages from them — are fed as context into a large language model, which then generates a response that draws on that context. The distinction matters: the model isn't answering purely from its training data; it's reading fresh sources in real time and synthesizing from them. This is why keeping your content current and crawlable matters for AI visibility.
If a model retrieves your page but the relevant passage is buried halfway down, the answer it synthesizes may not mention you. Pages that lead with a direct, self-contained answer give the model something quotable in the first few hundred words — where retrieval systems look first.
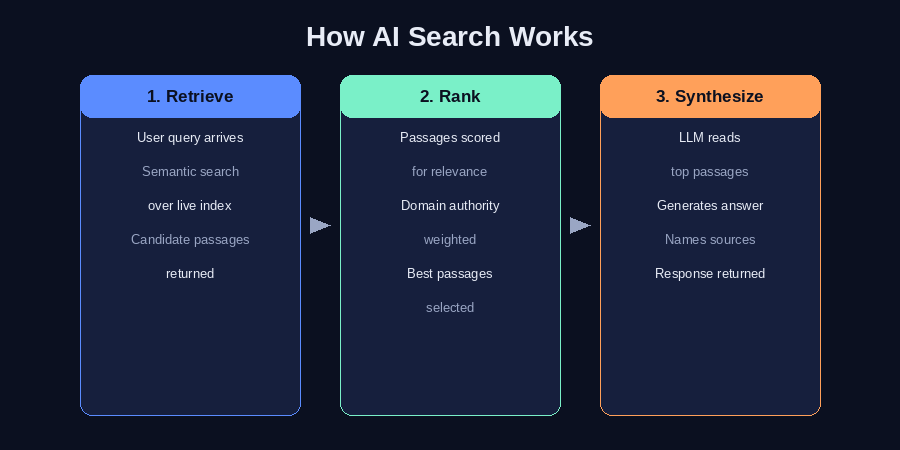
How does the engine decide which sources to use?
Source selection combines several signals. At retrieval time, the engine runs a semantic search over the index — matching the meaning of the query against document passages, not just keywords. Documents from higher-authority domains tend to appear more reliably in the retrieval set. After retrieval, a ranking or reranking step scores the candidate passages for relevance to the specific query. The model then synthesizes from the highest-scoring passages, and the sources it cites are usually those it leaned on most heavily during generation.
What makes a source get cited?
A source gets cited when it survives all three stages: it must be crawled and indexed, it must be retrieved as a relevant result, and it must contain a passage the model can confidently quote. Crawl access, relevance signals, and quotability are each necessary but not sufficient on their own. A page that's indexed but has hedged, vague prose will be retrieved and then bypassed for a clearer source. A page with excellent prose that blocks AI crawlers never gets retrieved at all.
Does AI search use real-time web results?
It depends on the engine and the query type. Perplexity always retrieves live web results and cites them. ChatGPT with web search enabled does too, though ChatGPT without web access answers from training data only. Google AI Overviews integrates live search results. Claude can search the web when configured to, but in its default state answers from training. For most informational queries — the kind where you want to be cited — the engines with live retrieval are the most important to optimize for, because they can find your latest content.
How does the model decide what to say about a source?
The language model generates text conditioned on the retrieved passages. It tends to quote or closely paraphrase sections that are concise, specific, and assertive — hedged, padded, or conditional prose tends to get dropped or reworded into something more confident. This is why content written to be quotable (short declarative sentences, named facts, clear claims) outperforms content written for human engagement metrics like time-on-page.
The short version
AI search retrieves documents, ranks passages, and synthesizes a new answer — it doesn't return a list. To be cited, your page must be crawlable, retrievable, and contain a passage the model can confidently quote. That pipeline determines what GEO is actually optimizing for.